
Review Mode
At present, most agent systems still remain at a stage where humans review the agent’s outputs. The dominant product forms can be divided into two categories:
The first category, such as Cursor Tab, where the model provides suggestions and humans decide whether to accept and execute them.
The second category, such as Claude Code, where humans define the task and review the plan, while the agent handles multi-step execution.
What Lanbow aims to build goes one step further: a Review Mode for Agent. Humans are only responsible for defining the objective and harness, while the agent continuously reviews its own execution traces, experiment results, and strategy performance during operation, and iteratively optimizes based on them. The goal is to achieve long-horizon autonomous execution and continuous optimization for enterprise growth scenarios.

Review Mode for Human
1.1 Cursor Tab: Human-in-the-loop on every step
1.1.1 Why Cursor Tab Emerged
The interaction paradigm represented by Cursor Tab is not fundamentally about letting the model autonomously complete an entire task. Instead, under current model capability constraints, it restructures long-horizon tasks into a series of local decisions that can be reviewed step by step by humans.
For long-horizon tasks, the overall success rate drops rapidly as task length increases. If a task is decomposed into n steps and the model’s success rate at each step is assumed to be p, then the overall success rate is approximately p^n. For a 10-step task with an 80% per-step success rate, the overall task success rate is only around 10%.
Under this condition, the most natural product design is not to let the agent execute fully autonomously, but to actively shorten the execution horizon, split complex tasks into many short-range decisions, and expose intermediate states at a level that humans can easily understand and intervene in. Cursor Tab is a typical example of this idea in coding: the model continuously produces local proposals, while the user incrementally accepts, rejects, or edits them, thereby constraining error accumulation in a long chain to a local scope.
This design is not unique to coding. In other agent products, there are also interaction patterns that explicitly expose intermediate reasoning to humans. One example is canvas-based systems such as Flowith: the agent presents intermediate reasoning nodes, task branches, and generation processes to the user, who can interrupt, edit, and rerun at any node. Whether it is Cursor Tab or these canvas-based products, the underlying logic is the same: when models still cannot reliably complete long-chain tasks, exposing intermediate processes converts long-horizon failure into local correction driven by human review.
1.1.2 Advantages and Boundaries of Cursor Tab
The core advantage of Cursor Tab is that by decomposing a task into local decisions that can be reviewed step by step, it significantly improves local execution reliability, interpretability, and error localization efficiency. But the cost of this mode is also clear: it relies heavily on humans being continuously online to review, its throughput is limited, and in essence it can only shorten long-horizon tasks through frequent review rather than truly delegating the full objective to the agent.
Therefore, Cursor Tab addresses the usability problem caused by insufficient long-chain execution capability in current LLMs, rather than representing the final form of long-horizon agents.
1.2 Claude Code: Human Reviews the Plan, Agent Executes
1.2.1 From Step-Level Review to Plan-Level Review
As models become more robust at multi-step execution, human review in human-agent collaboration shifts to a higher level. What humans submit to the system is no longer an execution process that must be guided step by step, but a relatively complete task. Accordingly, what humans review is no longer each intermediate action, but the plan generated by the agent to complete the task. In this mode, the agent continuously executes against the plan, including task decomposition, code modification, testing, fixing, and delivery, while humans mainly judge whether the plan is reasonable, whether the boundaries are correct, and whether the result meets expectations.
Claude Code’s Plan Mode is a representative example of this paradigm. Unlike Cursor Tab, it does not require users to continuously confirm every action. Instead, it is built around a simple interaction protocol: given a task, the agent first formulates a plan and then executes it. The shift is not merely that the execution chain for a single task becomes longer. More importantly, humans no longer intervene step by step in low-level execution, but instead manage multiple parallel tasks at a higher level. In other words, the value of Plan Mode lies not only in improving delegation for individual tasks, but also in significantly expanding human capacity for multitasking: once tasks are clearly specified, plans are made explicit, and execution status is continuously updated, humans can supervise multiple agents running different workflows in parallel.
For this reason, plan mode has further given rise to a class of products closer to managed agents. Multica is one example. Its core is not to keep optimizing one-shot prompt interaction, but to provide humans with a task board for assignment, progress tracking, and state coordination, making agents behave more like executors that can be assigned work, managed, and report blockers, rather than one-time tools. Its official positioning is an “open-source managed agents platform,” emphasizing turning coding agents into “real teammates” that support task assignment, progress tracking, and skill reuse. In this sense, Claude Code’s Plan Mode is not the endpoint, but a key transitional form in the evolution from copilot to managed teammate.
Source:Multica, https://github.com/multica-ai/multica?tab=readme-ov-file
1.2.2 Beyond Skipping Permissions: What Is Still Missing After Claude Code
In Claude Code, a representative phenomenon is that many users frequently use options such as --allow-dangerously-skip-permissions to bypass fine-grained permission checks. This is not just because users are willing to trade safety for efficiency. It reflects a more fundamental issue: once users start delegating work at the task level, if the system still requires approval at the action level, it effectively collapses back into step-level review. What users actually want to authorize is not a specific command, but the agent’s ability to complete a sequence of related actions within a clearly defined task boundary.
This also reveals the limits of plan mode. Once users want an agent to operate autonomously over longer horizons, the question is no longer simply whether permission prompts can be skipped, but whether the system has the mechanisms required to support sustained autonomous execution. This requires at least two broad classes of capability.
The first is multi-task parallelism and isolation. The agent must not only execute one task continuously, but also decompose multiple features into as independent subtasks as possible, identify shared dependencies and potential conflicts, and complete isolation and integration validation at the workspace, branch, or worktree level.
The second is execution trace logging and reuse. The agent must not only generate patches and run tests, but also structurally record what it has tried, where it failed, which tests have passed, and which boundaries have been verified. Otherwise, it can execute, but it cannot accumulate experience.
Therefore, the importance of --allow-dangerously-skip-permissions is not just that it relaxes permission checks, but that it points toward a broader shift: humans may no longer approve individual actions step by step, or even specify tasks in detail, and instead provide only objectives and constraints. In that setting, what the system needs is not merely a looser permission mechanism, but a review mode that can support long-running agents.
Review Mode for Agent
If the core of the first two types of systems is that humans review the agent’s work, then Review Mode for Agent points to a more advanced execution paradigm: humans define the objective and harness, while the agent operates continuously within that boundary, reviews its own execution process, and iteratively improves its strategy and capabilities through ongoing experimentation until the human objective is achieved.
Here, review no longer means checking what to do next. Instead, it becomes a continuous closed loop formed by the agent during execution: strategy proposal, experiment logging, evaluation, and refinement of benchmarks and test cases. The key to a long-running system is not just a stronger model, but an agent workflow organized around stable interfaces and an evolving harness system.
For this closed loop to truly work, the system needs at least four core components.
Trajectory logging + versioning. For an agent to review its own execution, it must first be able to record what it has done in a complete and replayable form. This record should cover the full execution trajectory and be queryable through the CLI in a reliable and convenient way, including the strategy proposed at each round, tool-call sequences, environment states, key intermediate artifacts, experiment configurations, code or configuration diffs, test results, benchmark scores, and final keep-or-rollback decisions. Just as importantly, what must be versioned is not the trajectory itself, but the algorithmic variant behind each attempt. The system needs to know which strategy, prompt, policy, code path, or configuration produced a given trajectory, so that the current attempt can be compared against prior algorithm versions rather than treated as an isolated outcome. Without trajectory logging, the agent cannot perform review; without algorithm versioning, it cannot form a stable path of iterative improvement over long-running execution.
Evaluation. Review is fundamentally an evaluation problem rather than a logging problem. For an agent to determine whether a strategy should be preserved, updated, or discarded, each execution or experiment must be mapped to a comparable performance signal. This signal may come from test cases, benchmark scores, online metrics, manually designed reward functions, or rule-based evaluators. Although the concrete metric depends on the application, its role is invariant: to provide a common basis for comparing runs and assigning credit to strategy updates. Without such an evaluation layer, accumulated logs are only passive records of execution and cannot support a true iterative optimization loop.
Benchmark / testcase generation and maintenance. In a long-running system, evaluation criteria are not static either. As the agent encounters more failure modes, edge cases, and adversarial scenarios, the system must continuously improve its benchmarks and test cases so that the evaluation surface keeps expanding. Otherwise, the agent can easily overfit to a narrow set of metrics while gradually drifting away from the true objective in the real environment. Therefore, Review Mode for Agent requires not only optimizing performance on existing benchmarks, but also continuously contributing to benchmark completion: turning newly discovered failure patterns, bad cases, and edge conditions into new test items, so that future optimization happens under stronger constraints. In other words, the benchmark is not just a static judge, but part of the system’s self-review capability.
Skill and policy update. If the first three layers address observability and evaluation—how to reconstruct past execution and how to determine whether an outcome constitutes an improvement—this layer addresses adaptation: how experience is converted into future capability. The value of agent review does not lie in repeatedly running the same propose-and-test loop, but in whether the system can extract reusable improvements from experience and incorporate them into its future behavior. These improvements may take the form of updated skills, refined policies, revised prompts, improved workflows, better tool-use strategies, or direct code changes. Only when the outcomes of past experiments can systematically influence future decisions does the system exhibit cumulative self-optimization. Otherwise, it remains a continuously running executor rather than an agent that improves over time.
Lanbow: A Review Mode for Agent System for Enterprise Growth
Advertising is a typical dynamic optimization problem, affected by multiple factors such as changes in platform traffic structure, creative fatigue, delayed attribution signals, and risk-control constraints. In this setting, the core capability of the system should not be to produce a one-shot optimal answer, but to keep experimenting, correcting, and moving closer to the objective over long-term operation.
Based on this idea, Lanbow builds a Review Mode for Agent system for enterprise growth: humans define the objective and harness, while the agent continuously records execution trajectories, launches strategy experiments, evaluates intermediate results, and iterates on its bidding algorithms through an experiment system. At the same time, the system accumulates and updates domain knowledge through a self-evolving Skill mechanism, and uses an extensible CLI executor to connect observation and action interfaces across multiple advertising platforms. Together, these components form a growth optimization loop that can run continuously 24/7.
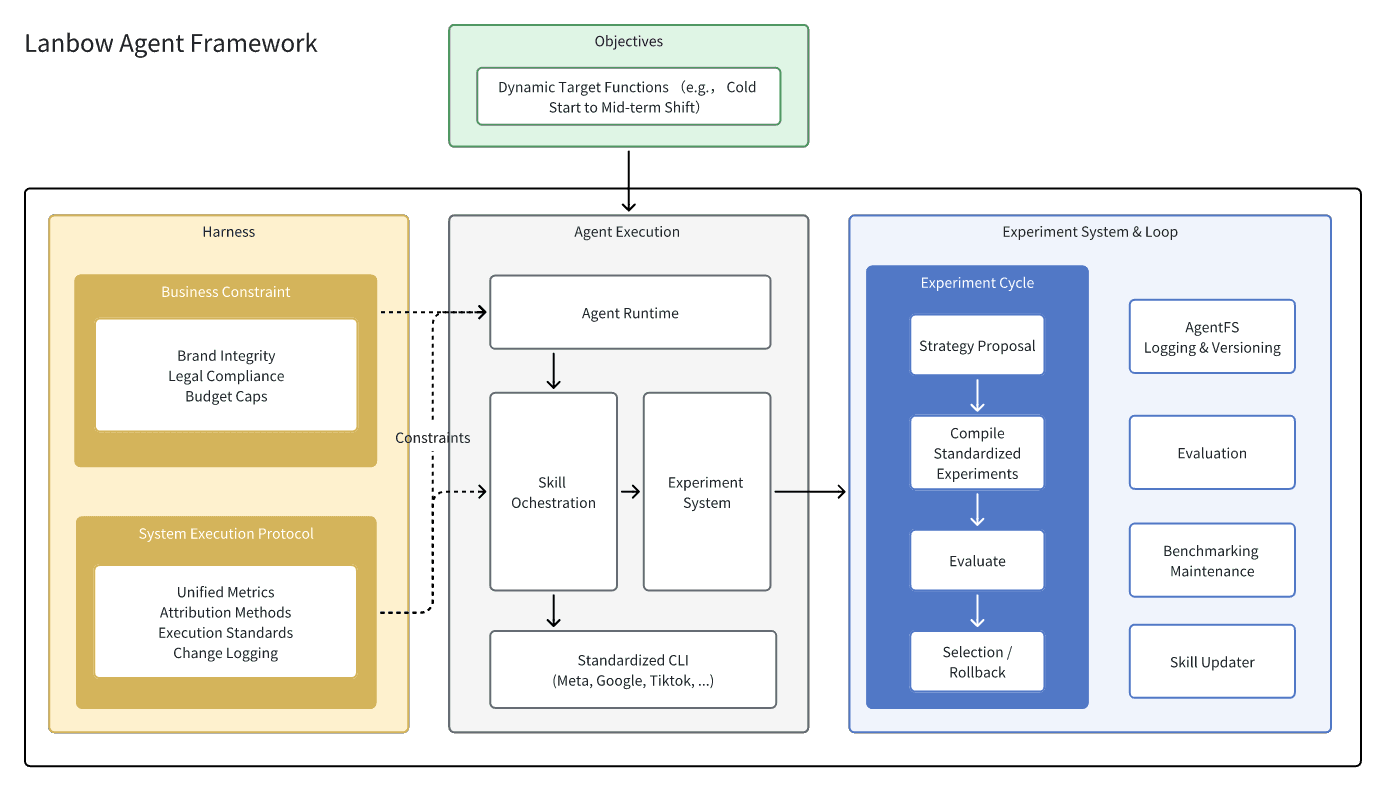
3.1 Objective & Harness: Definition of the Optimization Target and Operating Boundary
For an agent system that runs continuously in enterprise growth scenarios, the first thing that must be clearly defined is the system’s optimization target and the way it is allowed to optimize. The former is the objective; the latter is the harness. If the objective determines the agent’s direction, then the harness determines its boundaries, interfaces, and feedback loops. It organizes prompts, manages context, orchestrates tool calls, sustains multi-turn execution, and carries logging, validation, and observability mechanisms.
In enterprise growth scenarios, the objective cannot be reduced to a vague statement such as “improve ROI.” Real business goals usually involve multiple layers of constraints. For example, under a given budget, account structure, creative supply, and platform rules, the system may need to continuously optimize conversion volume, customer acquisition cost, payback period, retention quality, or profit margin for a given stage. More importantly, these goals are often not a single scalar objective, but a stage-dependent objective system. For example, the cold-start stage may prioritize exploration and volume growth; the middle stage may focus more on cost stability and attribution reliability; and the later stage may emphasize marginal return, budget utilization, and cross-channel coordination. Therefore, in Lanbow, the objective is a set of computable objective functions that can switch with business stages.
But objective alone is still not enough. Once the agent is allowed to run for a long time, its core problem is no longer “which button to click next,” but rather “under what regime should experiments be run, what is allowed, what is forbidden, when must execution stop, and what signals must trigger rollback.” This is exactly the role of the harness. In engineering practice, the harness is essentially a runtime governance layer: it provides the agent with state, tools, constraints, feedback loops, and a verifiable execution structure.
In advertising scenarios, the first part of the harness comes from the advertiser’s own business constraints. Ad optimization is not an open-ended problem that can be explored without limits; it is constrained optimization within the boundaries of brand, budget, compliance, and organizational process. These constraints include, but are not limited to:
Requirements at the creative and image level, such as brand visual consistency, prohibited expressions, legal boundaries, and regulatory rules across markets.
Requirements at the account and budget level, such as total budget, platform budget, campaign-level budget caps, limits on daily adjustment range, and scaling strategies at specific stages.
Business and risk requirements defined by the company, such as priorities across product lines and regions, whether short-term losses are acceptable in exchange for growth, and which abnormal spend or performance fluctuations should trigger automatic pause and human takeover.
The second part of the harness comes from the unified execution requirements imposed by Lanbow itself as a growth optimization system. Advertisers define business boundaries, but for an agent to run reliably over long periods across multiple ad platforms, it also needs a platform-agnostic and continuously optimizable system protocol. This includes:
Industry-specific attribution and metric definitions, including conversion definitions, attribution windows, deduplication rules, delayed postback handling, and cross-platform metric mapping. Otherwise, the agent will learn incorrect strategies from inconsistent feedback signals.
Basic experiment and execution protocols, such as which variables can be adjusted simultaneously, how long the minimum observation window should be, which outcomes count as valid signals, and which anomalies should trigger rollback. Together with structured change logs, execution audits, and exception-handling mechanisms, these protocols ensure that every action taken by the agent is traceable, interpretable, and reviewable.
In the context of Lanbow, the harness is essentially a system layer that turns the objective into an executable operating boundary. On one end, it connects the advertiser’s brand rules, budget limits, and risk preferences; on the other end, it connects Lanbow’s unified requirements for attribution, execution, auditing, and platform adaptation. Agent autonomy does not mean acting freely without constraints. It means continuously proposing strategies, executing actions, receiving feedback, and correcting its optimization direction within a clearly defined boundary. The experiment system discussed next further explains how, within the boundary defined by this harness, the agent systematically generates experiments, evaluates results, and drives strategy iteration.
3.2 Experiment System: Enabling Sustained Optimization
If the objective and harness define what the enterprise growth agent should optimize and within what boundary it may act, then the experiment system addresses an even more central question: once those objectives and constraints are given, how can the agent continuously generate new strategies, validate them, filter them, and turn experimental results into future optimization capability? In other words, Lanbow does not treat advertising as one-off task execution, but models it as a long-running, experiment-driven optimization process.
From a systems perspective, Lanbow’s experiment system can be viewed as integrating two complementary technical approaches. One is closer to the experiment infrastructure represented by Harbor (https://github.com/harbor-framework/harbor?tab=readme-ov-file): agent behavior is executed in standardized environments, experiments are evaluated in a structured way, and large-scale parallel rollout and downstream optimization are supported. Harbor defines itself as a framework for evaluating and optimizing agents and language models, supporting concurrent experiments across many environments and generating the rollouts needed for RL optimization. The other is closer to the autonomous research loop represented by autoresearch (https://github.com/karpathy/autoresearch): the agent no longer stops at executing a single task, but can autonomously propose modifications, run experiments, compare results, keep or discard changes, and iterate repeatedly within a given boundary. The core design of autoresearch is exactly to let the agent modify a controlled object and continuously experiment under a fixed budget and shared metrics, forming a sustainable propose-and-test loop.
Under this view, Lanbow’s experiment system can be summarized as a standardized loop: strategy proposal, experiment execution, evaluation, selection / rollback, and experiment memory with policy update. First, based on the current objective, the constraints defined in the harness, account state, and historical experiment records, the agent proposes a set of structured strategy hypotheses, such as adjusting budget allocation, switching bidding strategies, restructuring campaign layout, replacing creative combinations, or changing cross-platform budget transfer rules. The system then compiles these proposals into standardized experiments, including experiment settings and promotion criteria, and invokes platform capabilities through a unified CLI so that experiments across different platforms can be observed and compared under the same execution protocol. Next, the evaluation layer scores the results in a structured way, assessing not only short-term proxy metrics such as CTR, CVR, CPM, creative fatigue, and learning-phase status, but also medium- and long-term business signals such as CPA, ROAS, budget utilization, payback period, and order quality. The selection layer then decides whether a strategy should be promoted, kept under observation, or rolled back. Finally, the system writes the experiment trajectory, key changes, evaluation results, and failure modes into experiment memory, so that future agent decisions can explicitly depend on past experience rather than restarting from scratch each round.
On top of this, Lanbow also builds a dynamic benchmark maintenance mechanism. In advertising, the real difficulty is not defining the reward, but constructing a benchmark that can approximate that reward within a limited time window. On the one hand, this benchmark accelerates optimization by allowing the agent to judge strategies from intermediate signals before full business outcomes have fully materialized. On the other hand, it naturally faces two problems. First, benchmarks expire. Platform traffic structure, user attention distribution, creative competition, and delivery mechanisms are all constantly changing, so creative patterns, copy styles, or evaluation rules that once predicted final business outcomes may no longer hold in the future. Second, rewards can be distorted. Because of limited data scale, attribution delay, and pipeline noise, the system often has to rely on upstream proxy metrics such as CTR, engagement rate, and short-term click performance for early filtering, but these signals are not inherently equivalent to the business outcomes the enterprise actually cares about.
We encountered a typical example in real campaigns: the agent once delivered Arabic-language creatives in South Africa and observed an abnormally high average CTR of 36% over one week. If one looked only at upstream click performance, the system would almost certainly treat this as strong positive feedback and further summarize it as a creative pattern worth scaling. But further downstream, this traffic produced no effective conversions at all, revealing that it was only a false optimum amplified by local proxy metrics. This mechanism helps Lanbow continuously correct the system’s evaluation surface: on the one hand, it retires outdated benchmarks in time, preventing the agent from repeatedly reusing experience that no longer works in the current environment; on the other hand, it continuously turns newly discovered false-optimum patterns, distortion paths, and metric-gaming behaviors into new test items, constraint rules, and anomaly detectors. Only in this way can the agent continue to move toward truly effective optimization strategies in the real world, where the reward is clear but the environment keeps changing and observations are imperfect.
From an optimization perspective, Lanbow’s experiment system is not exhaustive search. Instead, under a limited budget, it prioritizes experiments that are both likely to improve the objective and informative in reducing key uncertainty. Advertising is fundamentally a noisy sequential decision-making problem with delayed feedback, multiple constraints, and a changing environment, so static rules or one-shot tuning are not sufficient for long-term optimization. For online allocation over discrete candidate strategies, creatives, or audience segments, a more natural formulation is the bandit setting. Optimistic exploration methods such as UCB prioritize candidates with either high current mean or high uncertainty, while Thompson Sampling allocates exploration budget more naturally to strategies that may be optimal but are not yet confirmed by sampling from the posterior distribution. In advertising, these methods are particularly suitable for online comparison across multi-creative traffic allocation, audience-level budget probing, and multiple bidding strategies.
At the resource allocation layer, Lanbow’s experiment system must also solve another practical problem: not every strategy deserves a full run. A more effective technical path here is not simply to improve the accuracy of one-shot judgment, but to stop low-potential experiments early through a multi-fidelity approach. This is exactly the idea behind methods such as Asynchronous Successive Halving Algorithm (ASHA): assign small budgets to many candidates first, eliminate clearly weak ones based on intermediate results, and then invest more resources into the few remaining high-potential options. Prior work shows that ASHA is designed for large-scale parallel settings and improves overall resource efficiency through aggressive early stopping. For advertising experiments, this means the system can first validate many candidate strategies with smaller budgets and shorter windows, and then focus more resources on the most promising ones, controlling experiment cost without sacrificing exploration breadth.
3.3 Self-Evolving Skill Algorithms: Distilling and Evolving Advertising Experience on a Standardized CLI
The skill system addresses how to turn execution trajectories validated by the experiment system into capabilities that can be reused reliably. At this layer, Lanbow designs skills as a form of procedural memory: not factual knowledge, but process knowledge about how to complete a certain class of tasks in a specific context. These skills are loaded on demand and can be created, modified, and deleted by the agent, forming a built-in learning loop.
In Lanbow, skill evolution is a continuous trajectory-to-skill distillation process. Its input mainly comes from two types of trajectories. The first is the agent’s own execution traces accumulated in the experiment system: the full process in which the agent proposes strategies, executes actions, receives feedback, and experiences rollback or retention under a given objective and harness. The second is the direct execution traces of human experts. In real advertising work, senior optimizers also directly invoke the agent to perform optimization and can intervene at any time during execution. These high-value action sequences contain not only the actions themselves, but also how timing, boundaries, and anomalies are handled.
This evolution process can be broken into four steps. The first is trajectory segmentation, which cuts long trajectories into relatively complete and semantically closed action units. A skill candidate must correspond to a clear local task, such as small-budget scaling during cold start, creative replacement after fatigue, conservative fallback under abnormal attribution, or cross-platform budget transfer for a certain class of accounts, rather than a collection of isolated single-step actions. The second is pattern abstraction, which extracts stable structure from multiple successful or high-quality demonstrations, keeps the truly transferable parts, and removes details tightly bound to a specific account, a specific creative, or accidental noise. The third is skill synthesis, which writes the extracted pattern into a structured skill with explicit trigger conditions, preconditions, action steps, observation metrics, and stopping conditions. The fourth is post-deployment validation: once generated, a skill is not immediately treated as a stable rule, but is first deployed in a gray-release manner on similar future tasks, where its gain, applicability boundary, and failure modes continue to be observed. Only after being validated across more scenarios is it promoted into the long-term skill library as an effective strategy.
The key challenge in this process is preventing skills from being misled by and amplifying local optima. For this reason, Lanbow’s skill evolution is tightly coupled with the benchmark maintenance described earlier. A skill is not a static rule, but a continuously updated strategy family: some are reinforced by new trajectories, some are replaced by better versions, and some are retired as the environment changes.
Within this framework, the CLI serves only as a stable execution surface that allows skills to be deployed across platforms. For example, a skill like “small-budget multi-creative probing during cold start” may appear at the execution layer as the following command sequence:
A standardized CLI does not mean different channels share exactly the same invocation pattern. Ad platforms naturally differ in campaign structure, budget hierarchy, creative organization, and delivery object models, so skills cannot simply be reused as one fixed command sequence. What Lanbow does is not force all channels into a fully uniform API, but abstract a higher-level layer of execution semantics, such as cold-start probing, winner-group scaling, creative replacement, budget transfer, anomaly fallback, and performance harvesting, and then let each channel adapter compile these semantics into concrete CLI calls consistent with that platform’s object structure.
Lanbow’s skill system serves as the layer that continually distills and updates the agent’s strategies. The experiment system generates and validates new trajectories in an open-ended search space; benchmark maintenance continuously refines the criteria for what constitutes useful experience; and skill evolution abstracts those experiences into reusable strategic structures that can be recompiled and executed across different channel configurations. Together, these components enable a qualitative improvement in the agent’s advertising capabilities.











