
Win on Ad Creative

I. Meta and Google Are Already Telling Us One Thing
If you've been reading Meta and Google's engineering blogs and earnings calls lately, one keyword keeps coming up: creative.
In December 2024, Meta Engineering unveiled Andromeda — a next-generation ad retrieval engine running on NVIDIA Grace Hopper. It filters billions of candidate ads down to roughly 1,000 before the auction, with Meta self-reporting "+6% recall" and "+8% ads quality on selected segments." Sitting on top of it, Advantage+ takes over targeting, bidding, placement, and even copy/visual variant testing — and on the most recent earnings call, Meta disclosed that this end-to-end AI ad product is now running at an annualized revenue rate of over $60 billion. On Google's side, Performance Max does almost the same thing in mirror image: an advertiser submits a goal and some assets, and bidding, targeting, and placement (across YouTube / Search / Display / Discover / Gmail / Maps) are all handed over to Google AI — Google has already started auto-generating voiceovers, vertical reformats, and shorter cuts for Performance Max videos.
Together, these two systems have pulled most of what used to be a media buyer's job — targeting, bidding, placement, A/B traffic splits — into the system layer. What's left for the advertiser?
Only "creative."
This isn't just a slogan. Since spring 2025, Meta has been repeating an official talking point in sales decks and data-science publications: "creative is the new targeting." Behind it sits empirical evidence Meta has published itself: about 56% of conversion outcomes can be attributed solely to creative factors; advertisers who switch on Advantage+ creative see an average +22% ROAS. In an interview with Stratechery's Ben Thompson, Zuckerberg pushed it one step further — "come up with, like, 4,000 different versions of your creative and just test them" — and the number of advertisers using Meta's video-generation tools grew +20% quarter over quarter in the most recent quarter.
Put another way: once the algorithms eat targeting, bidding, and placement, the creative itself becomes the last remaining lever for differentiation. Same product, same audience, same budget — version A delivers 3× ROI while version B gets shut down — and this gap is being amplified by the very automation systems doing the buying.
We've reproduced this in our own data. In a recent internal backtest comparing thousands of paired adsets, changing only the image (audience held constant) opened up significantly larger performance gaps than changing only the audience (image held constant) — the difference was statistically significant. In other words, once AI takes over targeting, bidding, and placement, what's left to explain the gap is mostly the creative itself — the same finding as Meta's 56%, expressed in our own numbers.
But here's the contradiction:
AI-generated images, AI-generated video — the technology has long since gone mainstream. Midjourney, Sora, Kling, Runway — anyone can spend $20 and play with them all day. Model capability isn't the bottleneck.
But ask any half-serious performance marketing team why they don't just plug AI-generated creative straight into their ad accounts, and the answer is remarkably consistent:
"We don't dare."
This isn't a model problem. It's a domain problem.
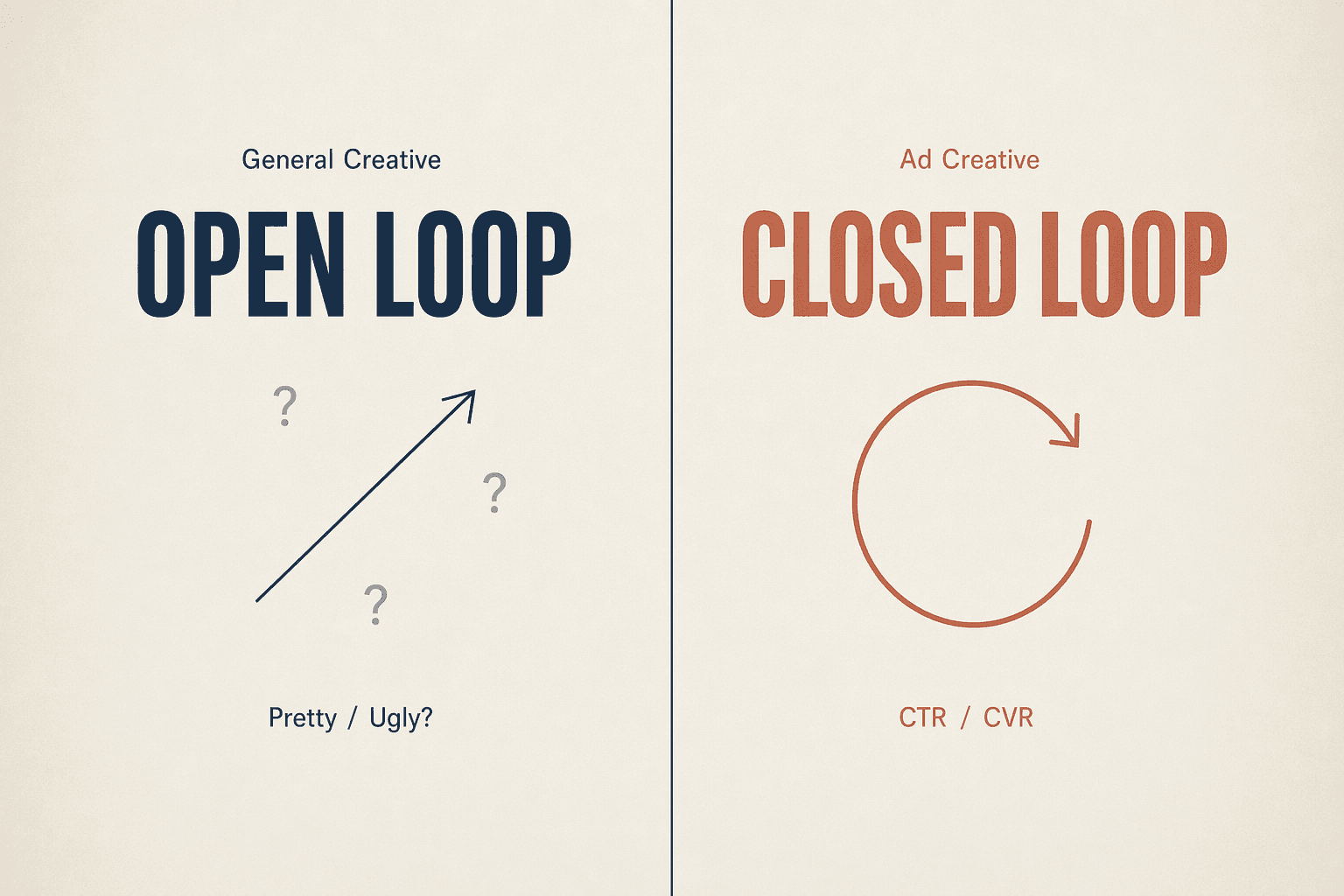
II. General Creative vs. Ad Creative — The Gap Isn't Aesthetics
This is the first insight I want to make.
General creative has no objective right or wrong.
You ask Midjourney for a cyberpunk cityscape; version A vs. version B — which is better? There's no answer. It's an aesthetic question. Aesthetics are subjective, vary wildly between individuals, and have no ground truth. Every general-purpose AI image model is, fundamentally, optimizing for "what humans find pretty" — a fuzzy target.
Ad creative has objective right or wrong.
Two versions of the same product's creative: A delivers CTR 4.2%, CVR 1.8%; B delivers CTR 1.1%, CVR 0.3%. Which is better? No debate. That's the answer. "Good" in advertising is a measurable, attributable, comparable, objective signal.
This one-word difference determines two things:
General creative AI can only run "open-loop" — once it generates an image, that's it; nothing tells the model whether it got it right or wrong.
Ad creative AI can "close the loop" — every image that ships brings back CTR / CVR / ROAS feedback, telling the model "this style works, that composition doesn't."
This is the fundamental difference between AI ad creative and "AI image generation" — not a stronger model, but having feedback.
It sounds obvious, but most products on the market today that wrap AI image generation in an "ad creative tool" wrapper haven't actually solved this. They live at the level of "better prompts" and "newer models" — the same upgrade ladder as general creative AI — but they never cross the gap from open-loop to closed-loop.
One counter-intuitive finding worth sharing — high CTR is not the winner.
We ranked thousands of internal adsets by performance, compared the top 100 against the bottom 100, and reached three conclusions:
CTR: top performers' average CTR was actually lower than the bottom's
CVR: top performers' CVR was nearly 10× the bottom's
CPM: top performers' CPM was a fraction of the bottom's
What does this mean? Anyone treating CTR as their North Star metric may be systematically pouring money into "clickable but unbuyable" creative. Good ads don't attract the most clicks; they attract the right ones. CVR is the highest-leverage signal, CPM second, CTR a distant third.
This is the kind of conclusion you can never reach by looking at generated images alone — without running spend, without accumulating data, without building a closed loop.
III. Ad Creative Engineering Isn't Prompt Engineering — Three Real Decisions
Getting this loop running is one thing; getting it to run reliably is another.
After half a year on two distinct product lines — novels and fintech — we're increasingly certain of one thing: what really decides whether a piece of creative can ship isn't which model you used, but how to build a creative harness around the real capabilities of today's models so it reliably produces shippable output. This layer isn't about clever prompts — it's about a handful of concrete technical decisions. Three of the most representative:
Decision 1: Character Consistency — Don't Trust a Single Model
One of the most common failure modes in ad video: in the same clip, the protagonist's face changes between shot 1 and shot 2. With multi-shot longer videos it's even worse — after five cuts the lead has become unrecognizable.
The generic solution is "train a personalized model" — slow, expensive, inflexible. That's not our path.
Our technical approach: lift character generation out of video generation and make it a separate upstream step.
Before any video enters the generation layer, we use Seedream 5.0 Lite to generate 1–2 character reference portraits — this step only answers "what does this person look like," carrying no shot/action/lighting burden. Then this portrait set is fed as reference images into every shot generated by Seedance, so every shot's protagonist "grows out" of the same portrait set.
The benefit: every video's protagonist looks different (avoiding viewer fatigue), but within any single video, the protagonist across multiple shots is guaranteed to be the same person (no continuity breaks). We do not rely on a video model's own cross-shot consistency — at today's model capabilities, isolating "what does this person look like" as a separate upstream step is far more reliable than hoping an end-to-end model handles it cleanly in passing.
Decision 2: Subtitles — The "Small" Thing That Decides Shippability
A real case: we generated a fintech KOC-style video, and Seedance rendered the customer's brand name (let's call it "X-Cash") as "X-Cosh" — one letter off. Platform review rejected it instantly. Reason: misleading brand presentation.
This isn't bad prompting. This is today's video models still being unstable at rendering on-screen text — especially for brand names, compliance numbers, license IDs — anything where a single character error is fatal.
Our technical approach: lift subtitles out of the generation model entirely.
Seedance generates a text-free original video, with the prompt explicitly stating "no text in frame"
Pillow renders subtitle PNGs line by line from a subtitle file
ffmpeg overlays them onto the original video at precise timestamps, producing the final output
This pipeline is ugly, unsexy, very "old-school engineering." But honestly: this is a current workaround, not a permanent law. When video models improve by another half-generation and can stably render brand names and compliance characters, this layer disappears. We keep it because right now it's the line between "shippable" and "not shippable."
Decision 3: Verification Isn't a Single Score — It's a 15-Dimension Two-Track Check
Whether an ad creative is good isn't something you can hand to an LLM for a one-shot "looks fine" verdict. We built verification as two parallel tracks.
General quality track: 15 dimensions across four categories — visual defects, layout & hierarchy, brand consistency, expression & compliance. Every dimension corresponds to a real rejection or low-performance failure mode, not abstract aesthetics.
Business constraint track — product-aware checks with the product brief in context:
Does the character match the novel's setup (race, age, physical traits — no swapping)?
Are brand logo, compliance characters, APR figures, CTA all present?
Does it pass the platform's industry policy (Meta / TikTok / Google each have different red lines)?
Each product's rules can differ; the rules themselves live in the product config and travel with the product.
Both tracks must pass for a creative to ship. Either track's rejection comes back to the generation layer with concrete improvement notes for a refinement pass, capped at a few iterations.
This layer is still LLM-based today — humans write rules, large models interpret. It already catches the vast majority of obviously-unshippable creative before launch. But more importantly — it's accumulating real spending feedback every day: which creative actually delivered high CTR, which got rejected by the platform, which converted well but didn't retain. That data hasn't yet been fed back into the model, but it's becoming the ammunition for the next stage — which is what the last two sections are about.
IV. Mining the Reward Signal — Let Real Spend Define "Good"
At this point we have to answer a harder engineering question: this verifier, this future reward model — how does it actually "know" whether a creative is good?
The easiest wrong answer: "let GPT take a look and score it." We do have that layer, but at its core it's making generic aesthetic and compliance judgments, not predicting "will this make money in market." It can catch obvious image errors, compliance problems, and brand defects — but it can't answer "will this clean-but-simple creative outperform that polished-but-busy one in market."
To answer that, the reward signal has to come from real spend data itself, not from any large model's intuition. Our approach is to process daily-incoming real-spend data into "paired evaluation samples." Roughly like this:
Step 1: "Same advertiser, same product, same time window" as the basic unit
When you open up real spend data, the biggest noise isn't the creative — it's audience, daypart, bid, placement, industry baseline traffic, and market. A clothing ad vs. a fintech ad — CTRs aren't comparable; a US fintech ad vs. an Indonesian fintech ad — CPMs aren't comparable either; the baselines are entirely different.
So we slice by campaign: a single campaign typically contains a few to a dozen adsets, sharing the same advertiser, same product, same time window, same audience targeting, and same market. This is the "within-bubble comparison" after variables are controlled — locking down external noise as much as possible.
Step 2: Normalize on "industry × market"
Every industry has its own CTR / CVR / CPM baseline: 5% CTR is normal in gaming; 1.5% CTR is top-tier in fintech. The market dimension is equally extreme — CPMs in developed markets (US, UK, Japan) are often several times those in developing markets (Indonesia, Brazil, Pakistan); the same creative shown in different countries can produce CPMs that aren't even on the same scale. Comparing absolute values across markets and industries can never tell you which creative is actually better.
Our approach: compute the baseline mean for each metric on a 2D "industry × market" grid, then divide each adset's actual value by the corresponding cell's mean to get a "relative performance." This strips out both the industry baseline and the market baseline; what's left is the creative's own ability.
We then collapse multiple metrics into a single composite score — CVR's relative value carries the main weight (this is where the user actually pays), CPM is inversely weighted (lower is better), CTR gets a light contribution, and the whole thing is multiplied by total spend as a scale weight. This composite score is what we use as the "winner signal."
CTR is intentionally down-weighted here — it's too easy to mislead. A clickbait visual can spike CTR, but the users it pulls in won't buy.
Step 3: Pair up — same advertiser, different creative
After scoring, the critical step is pairing:
Take the N adsets under a single campaign. Find the highest-scored and lowest-scored pair — as long as their creatives are completely different, that pair is a valid training/evaluation sample.
Why does this step matter? Because it isolates "creative difference" from "every other difference":
Same advertiser → same product power
Same campaign → same audience, daypart, budget allocation rules
Industry × market normalized → baseline floor removed
The only variable left is the creative itself
In each pair, the performance gap between "winner" and "loser" is the clean reward signal contributed by creative — not guessed by a model, not judged by a designer's experience, but cast by real users with their wallets.
We also construct a contrastive class of samples: the same creative shown to different audiences, measuring how much performance variation audience alone explains. When we put the two classes side by side, the result is: the gap caused by creative is substantially larger than the gap caused by audience.
What does this mean? It means that once Meta and Google have handed targeting over to algorithms, the remaining human-controllable variable — "switch the creative" — is exactly the higher-leverage variable.
A Counter-Intuitive Fact: Pretty ≠ Wins
After looking at enough of these paired samples, a wince-inducing pattern keeps showing up:
The pair's higher scorer has a noticeably rougher composition
The pair's lower scorer is the version the designer would themselves pick as "more polished"
This isn't sporadic — it's patterned. The most common "pretty but lost" modes:
Studio-grade product lighting, but missing the "use case" — viewers see a product photo, not a moment in someone's life
Price tile, CTA button, and value-prop text laid out tidily, but the visual center is fragmented; the first second doesn't grab anyone
A "premium-feeling" minimalist composition, but no emotional anchor; users scroll right past
What they got wrong wasn't aesthetics — it was assuming pretty = winning. The actual winners often look visually rougher, but with a clearer focal point, stronger emotion, more direct expression.
This counter-intuitive fact is exactly why the reward signal matters — it's the first time "looks good" and "makes money in market" are explicitly separated. A rule-based verifier will never learn this, because rules are always written in terms of "pretty." Only by feeding real paired samples from actual spend back into the model can it gradually develop the engineering instinct of "I can tell at a glance whether this will scale."
V. Tying It All Into a Closed Loop
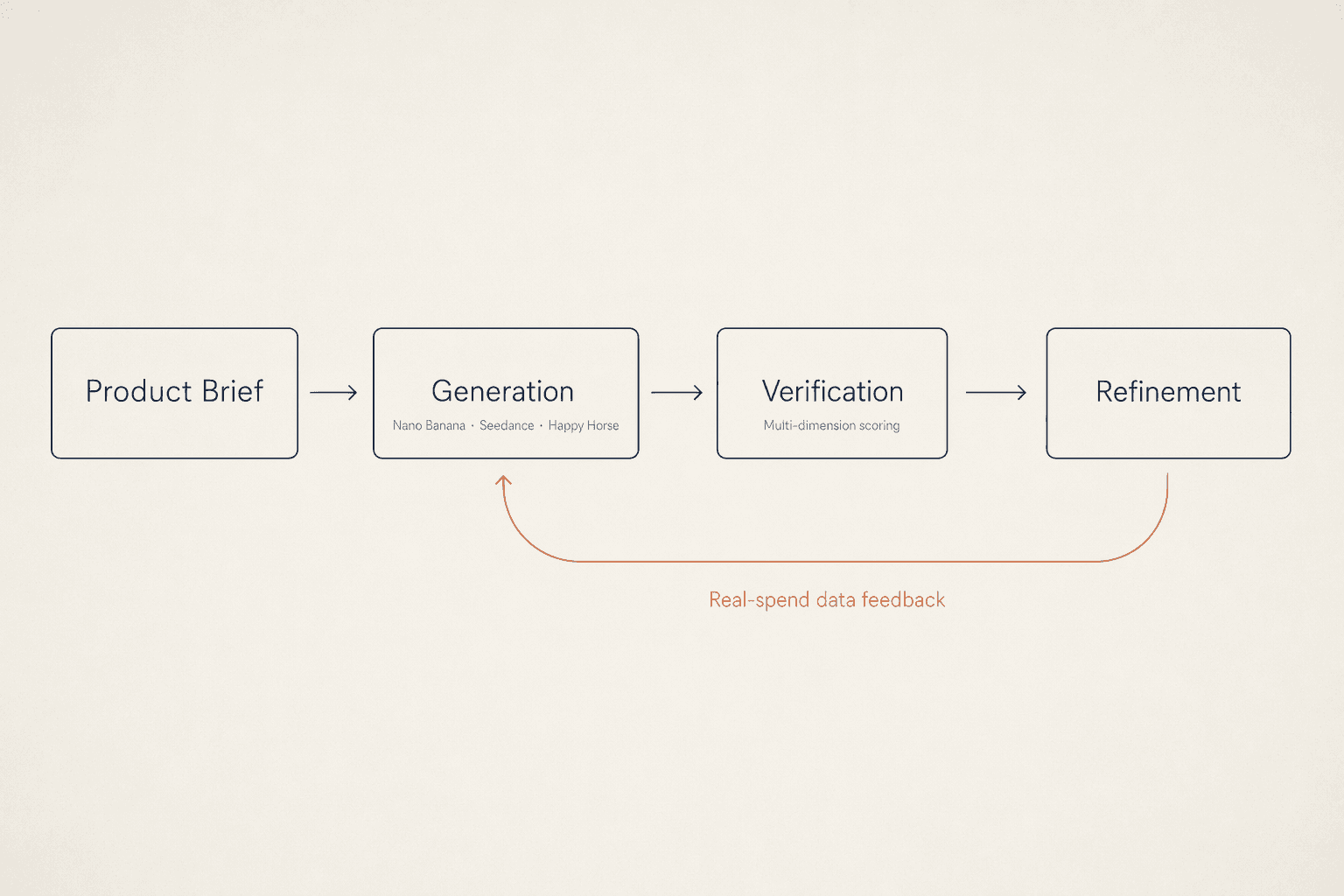
Stack all these decisions in their engineering order and you have the full picture of our ad creative generation framework.
Creative layer solves "come up with ideas." Scenario extraction, reinterpretation, batch ideation — the core is translating plot into emotion. A "hospital scene" in a novel gets rewritten in our system as "shirtless male lead carrying the unconscious female lead down the corridor" — same plot anchor, completely different visual tension.
Generation layer solves "produce the image." Images via Nano Banana; videos via Seedance, Veo, and Happy Horse; character consistency owned by Seedream. Each layer uses the model best fit for it — no forced end-to-end.
Verification layer solves "is it right." 15-dimension two-track scoring + failure-with-notes loop back to generation for refinement; iterate to convergence or abandon.
Data layer solves "what counts as good" — and this is the soul of the closed loop. Every shipped creative carries an ID and brings back spend data, accumulating training material for the next-gen verifier.
We've run this same framework on two product lines with completely different shapes — one driven by emotion and plot, the other by compliance and competitive benchmarking. The standards for "what counts as good creative" differ wildly across them, but underneath they share the same closed loop: scenario extraction → generation → two-track verification → data feedback. That fact convinces us the paradigm isn't an accidental local solution for one industry — it's transferable.
VI. Next: Making the "Judge" Actually Learn
A confession is in order here.
Our current verifier is still, essentially, a rule-aware judge — it recognizes what "obviously unshippable" looks like, but asking it to predict "will this make money in market" is beyond what rules can do.
The good news is the data is accumulating. Every day, hundreds of campaigns, thousands of adsets, real spend data spanning a dozen industries flow back in — paired, normalized, scored. The full pipeline is wired up.
Only one step remains: actually using this data to train a dedicated reward model.
What happens after that?
The current verifier keeps guarding the "quality gate" — visual defects, compliance fields, brand consistency; that layer doesn't go away. The change is on the other side: the reward model takes over the "winner gate" — giving a data-backed performance estimate before a creative ships. Every new creative the generation layer produces now passes through two gates: one judges can it ship, the other judges will it win. And the iteration feedback signal stops coming from "what our designer thinks" — it comes from a prior compressed out of hundreds of thousands of historical real-spend creatives.
From there, the whole generation system stops being just "a hand that can paint" and becomes "an eye that understands advertising."
VII. Back to the Opening Question
When Meta and Google have automated targeting, bidding, and placement, and creative becomes the last lever — who wins?
The answer isn't "whoever uses the newest model." That layer has already been commoditized; anyone can use it.
The answer is "whoever closes the loop first, and starts accumulating domain data first."
Once the loop spins, it compounds. Every day of creative generation, every spend signal that comes back, every accumulated definition of "what counts as good" adds a tiny piece of un-copyable domain know-how to tomorrow's model. This is a gap models alone can't close. It's a gap in engineering paradigm.
We're already running.










