
Agentic Engineering
"Run my ads, show me the results, help me optimize."
This is the request we hear most from users. Not a control panel, not a data dashboard — they want an agent. Salon owners, gym trainers, cross-border e-commerce sellers — most don't understand ad operations and don't want to. They need to hand it off and see results.
This request has two layers:
Decision layer: Deciding what to run and how to optimize — audience selection, budget allocation, creative iteration. Fundamentally an algorithmic problem.
Execution layer: Completing multi-step, multi-branch campaign workflows — from authorization to activation, with runtime decisions interspersed throughout.
The decision layer — audience intelligence, budget optimization, real-time bidding signals — is where the real battle is. Built on proprietary dynamic optimization algorithms and closed-loop validation models, Lanbow is turning unstructured market competition into deterministic, machine-measurable computation. But that's a story for another post. This one focuses on the execution layer — the process that turns "run my ads" into 20 API calls.
The hard part of execution isn't any single API call. It's the dynamic handoffs between steps — what to do next, how to handle failures, which decisions the Agent makes autonomously, and which require user input. After two iterations, we discovered: the best orchestration logic is neither code nor pure LLM reasoning. It's a markdown document.
These lessons come from Lanbow, an enterprise growth decision system built by Sandwich Lab. Under the hood, Lanbow runs a proprietary campaign intelligence engine — combining cross-market signal fusion, real-time creative scoring, and adaptive budget allocation across heterogeneous ad networks.

Agent execution architecture
Take Meta ad campaigns as an example. "Complete a campaign for the user" sounds simple, but it's actually a long-running hybrid orchestration task — involving AI decisions, human participation, and runtime branches at every turn.
A single workflow involves 8 steps:

It looks linear, but it's full of runtime branches. Typical issues include:
Is the user's authorization still valid? What if it's expired?
Should creatives be AI-generated or use existing assets? What if generation fails?
The user didn't mention a Pixel ID — should the Agent proactively suggest conversion tracking?
Should the budget use ABO or CBO? This isn't something the Agent should decide on its own.
In other words, this is a classic DAG-meets-human-in-the-loop problem: steps have dependencies, branches, and decision points that require human judgment.
We extracted these concerns into an independent orchestration layer — determining what to do next, how to recover, and what requires user escalation. The interaction layer (conversational UI) changes rapidly, but orchestration logic is relatively stable. Separating the two lets both sides evolve independently.
Orchestration layer evolution: from Workflows to Skills
The orchestration challenge is clear: finding the right balance between step dependencies, runtime branches, and human decision points. But what's the right medium for orchestration? We went through two iterations:
Workflows: MCP tools + code-defined DAGs, with some nodes implemented by Agents while the overall flow was defined programmatically.
Skills: CLI + markdown document orchestration, with the entire workflow executed autonomously by the Agent within a document framework.
Workflow automation
The first step was wrapping the ad platform APIs as a toolset via MCP — project management, creative generation, ad assembly, budget adjustment — for structured LLM access. But in 30 internal test runs, the completion rate was under 60%: wrong step ordering, missed prerequisites, autonomous decisions where none were warranted.
The problem wasn't LLM capability — it could orchestrate, but it didn't have an "operations manual." So we added a second layer: a DAG orchestration engine that wired tool calls into fixed workflows via code. The completion rate rose to roughly 85%, but the code had already grown past 400 lines and was still expanding — each runtime branch was a conditional node, and every new edge case meant code changes, testing, and deployment. Worse, business rules were coupled with execution logic: changing a single rule required understanding the entire orchestration structure first.
DAGs rely on determinism for reliability, but when branches grow complex enough, that determinism itself becomes unmaintainable. The interaction layer iterated fast, but orchestration logic was locked in code; every adjustment required a backend deployment. Runtime logic grew increasingly complex, and development costs scaled exponentially. We needed to decouple orchestration logic from code.
Skills as orchestration
We needed a new approach to orchestration: one that combined the structure of code with the flexibility of natural language. We landed on markdown — and for good reason.
Documents are the most natural medium for LLMs. They were trained on vast quantities of operations manuals, technical documentation, and process guides — they inherently understand the structure of "prerequisites → steps → error handling." Compared to code DAGs, markdown offers both structure and flexibility: structured enough to guide execution order, flexible enough to allow LLM reasoning within the framework.
Anthropic explored this idea in their Equipping Agents with Agent Skills blog post, and Claude Code's Skills mechanism puts it into practice — defining Agent behavior patterns through markdown documents.
Each Skill is a markdown document describing a complete workflow — including prerequisites, step sequences, decision points, error recovery strategies, and global rules.
A simplified Skill example:
After reading the Skill, the LLM executes step by step within the document framework:
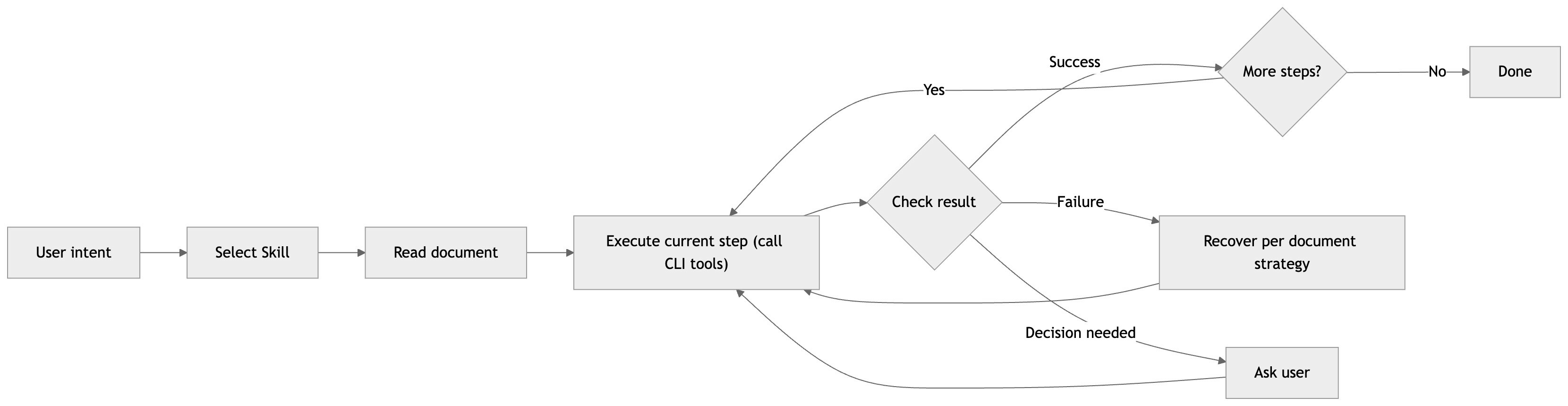
Results: the completion rate improved from ~60% (MCP phase) to 92%+, measured across ~200 campaign sessions over three months. The LLM didn't get smarter — we gave it guidance at the right granularity. Not line-by-line instructions, but an operations manual. It covers common scenarios (~80%), with the remainder handled by LLM reasoning within the framework. When new scenarios arise, updating the document takes effect immediately, with no deployment required.
Agentic system design practices
The evolution from Workflows to Skills is a shift from automation to agentic design. Traditional workflows enumerate every path in code; agentic systems let LLMs reason within a structured framework. This changes the answer to "who handles uncertainty": from developers pre-coding every path to Agents making runtime judgments.

Agent architecture
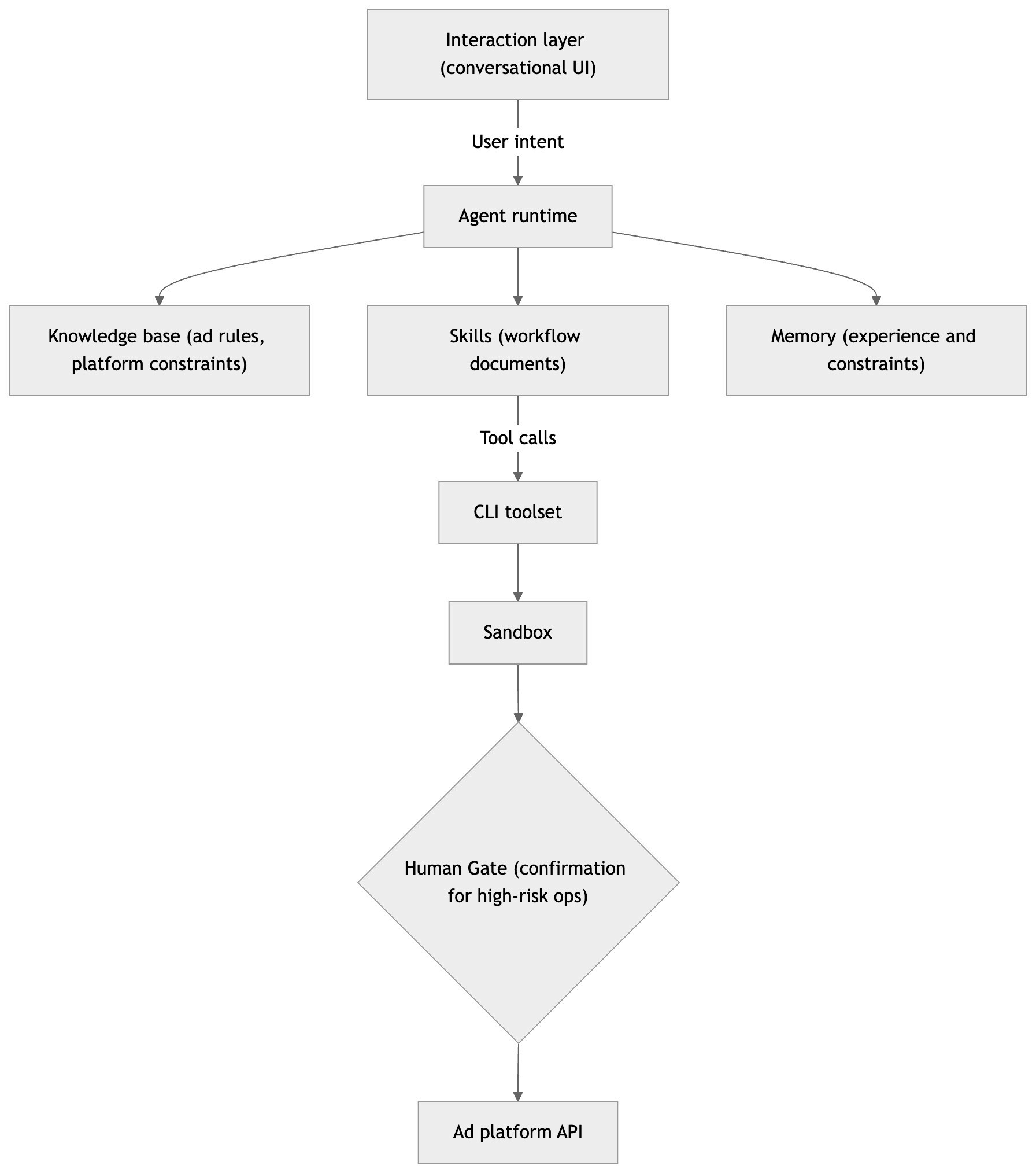
The Agent runtime comprises six components — four functional layers and two safety mechanisms — each addressing a different concern. User intent triggers Agent dispatch, and the Agent accesses each layer as needed during reasoning:
A complete invocation path: user intent → LLM reads Knowledge base and Memory for context → reads the corresponding Skill → calls CLI tools → Sandbox validates parameters → high-risk ops go through Human Gate → executes and reasons about the next step → writes results back to Memory.
CLI
Each tool maps to a single atomic business operation (project management, creative generation, ad assembly, budget adjustment), exposed via MCP with structured JSON inputs/outputs, clear error messages with recovery suggestions, and idempotent create operations.
Why the CLI form factor? LLMs handle CLI interactions well — their training data is full of them. Anthropic introduced the ACI (Agent-Computer Interface) concept in Building Effective Agents, noting that tool optimization often exceeds prompt engineering effort. Tool definitions are themselves prompt engineering — they need usage examples, edge cases, and clear boundaries with other tools.
Skills
Skill design involves three key decisions. Granularity: one Skill maps to one complete user-facing task — "launch a Meta ad campaign" or "optimize an active ad." Too coarse and the Agent loses direction; too fine and it degenerates into tool invocation. Coverage: follow the 80/20 principle — explicitly cover 80% of common scenarios, leave 20% for LLM reasoning. Skills work best at 100–150 lines; our first 500-line version caused information overload. Loading strategy: lazy loading — Skills are pulled in only when the Agent determines relevance, following Anthropic's "attention budget" concept from Effective Context Engineering for AI Agents.
Knowledge base
If Skills are the "operations manual," the knowledge base is the "industry standard" — global constraints spanning all Skills: ad hierarchy structure, budget rules, optimization mappings, and safety red lines. We embed it directly in the system prompt (~150 lines, ~4K tokens) — no RAG needed, since the volume is manageable and changes are infrequent.
Memory
Memory stores per-tenant contextual information: user preferences, historical campaign parameters, and past optimization results, implemented on the file system. Its purpose is to let the Agent accumulate experience — remembering that a user prefers ABO mode, or that a certain style direction caused creative generation to fail. The distinction from the knowledge base: knowledge base holds universal rules ("CBO budgets are set at campaign level"), while Memory holds personalized experience ("this user had poor results with CBO — recommend ABO first").
Sandbox
Ad operations involve real money. The sandbox layer sits between CLI tools and the actual API, performing parameter compliance checks, dry-run simulation via platform validation endpoints, and flagging critical operations for secondary confirmation — intercepting obvious errors before the call to reduce the cost of trial and error.
Human Gate
Not every operation should be left to the Agent. Human Gate defines three tiers: autonomous execution for low-risk, reversible operations (pausing ad sets, pulling reports); notify-then-execute for medium-risk operations (fine-tuning bids within approved ranges); and must confirm for high-risk, irreversible operations (activating ads, increasing budgets, changing creative direction). These tiers are encoded in both Skills and the CLI tool layer — even if a Skill is ambiguous, the tool layer enforces confirmation for high-risk operations.
Development practices
Skill development standards
Every Skill follows a consistent structure: YAML frontmatter, prerequisites, step sequence, decision points, natural language error recovery strategies, and global rules.
Publishing and verification
All Skills are managed in Git, co-located with code. Every change is linked to a specific issue — before version control, a single-line Skill edit could shift Agent behavior with no way to trace the cause. The publishing workflow is: edit document → PR review (checking for ambiguous wording and broken step dependencies) → merge, and it takes effect immediately. Compare this to the code DAG era: edit → review → test → build → deploy. Skill iteration cycles dropped from days to hours, and rollback is a single git revert.
Observability
When an Agent fails, there's no stack trace — just tool calls and LLM reasoning. We diagnose issues through complete session trace logging, weekly sample reviews, and deviation analysis against Skill expectations. Over time, a clear failure distribution emerged: tool-layer errors ~70% (API timeouts, auth expiration — not Agent problems), reasoning errors ~15% (wrong parameters, skipped steps), and Skill gaps ~15% (uncovered edge cases — the easiest to fix, since you just update the document). This distribution itself validates the Skills architecture: most improvements only require document changes.
Security
Ad operations involve real money, so security follows one assumption: the LLM is untrusted. Three deterministic layers serve as safeguards: (1) Skill layer — critical rules written in the document ("new ads must be in PAUSED state"), (2) CLI tool layer — the same rules hardcoded in tools, intercepting LLM oversights, and (3) Hooks layer — event-driven validation scripts checking budget limits and required fields, running in deterministic code independent of LLM judgment. The three layers progressively tighten, ensuring safety even when the LLM misbehaves.
Token usage runs ~15–25K per session (~$0.10–0.20), with end-to-end campaigns completing in 30–60 seconds.
The ad optimization expert Agent in practice
Launching campaigns is just the beginning. Ongoing optimization — interpreting data, deciding what to adjust, avoiding wasted spend — is what SME users struggle with most. The optimization expert Agent handles this as a continuous Diagnose → Suggest → Execute loop:

The Agent pulls 7-day metrics, compares against baselines, identifies anomalies (e.g., CTR dropped 30% → likely creative fatigue), and generates actionable suggestions tied to specific metric changes — with conservative and aggressive options for the user to choose from. After confirmation, it executes and schedules a 24-hour performance review, closing the loop. All six architecture components participate: the knowledge base provides diagnostic thresholds, Skills define the workflow, CLI tools execute operations, Memory tracks user preferences and past results, Sandbox validates parameters, and Human Gate enforces confirmation for high-risk changes.
The efficiency gains are significant: diagnosis that previously took 24–48 hours now completes in under 5 minutes, optimization shifted from weekly manual audits to continuous monitoring, and ~80% of routine operations are handled autonomously.
What we've learned
From Workflows to Skills, we observed three systemic shifts: orchestration logic migrated from code to documents, release cycles shrank from days to minutes, and Skill maintainers expanded from developers alone to include product and operations teams. These aren't differences in engineering preference — when the executor shifts from a deterministic program to a probabilistic LLM, the optimal medium for orchestration changes with it.
Documents as orchestration — by writing three tiers of autonomy (autonomous execution / notify-then-execute / must confirm) into Skills, we compressed conversation turns from 12 to 5, letting the Agent be decisive when it should be and cautious when it must be.
Documents as experience — 4 lines of natural language error handling strategy replaced ~80 lines of try/catch. More flexible than hardcoded logic, while the safety floor is guaranteed by the dual layers of Skills + CLI tools.
This is the core value of Skills: distilling team experience into executable document assets — editing a document is editing product behavior.
Looking ahead
CLI + Skills are becoming an orchestration paradigm
Claude Code's Skills ecosystem (OpenClaw) is growing rapidly, with developers defining Agent behavior through markdown documents. CLI is the tool interface LLMs know best, and markdown is the most natural knowledge medium — when both are good enough, the orchestration layer doesn't need code. Natural language is the best orchestration language.
Challenges ahead
We believe agentic systems will gradually replace traditional automation workflows for complex business processes. But large-scale adoption faces core challenges: defining "correct" for probabilistic output requires entirely new evaluation frameworks; every LLM call has a cost that fixed code doesn't; users need incremental trust-building before handing real money to a probabilistic system; and debugging an LLM's decision chain demands structured traces far beyond traditional stack traces.
Where we're investing next
We're building an automated eval framework to make Skill iteration data-driven rather than intuition-based. Beyond that, we're pursuing constraint-driven autonomous execution — shifting from "user instructs → Agent executes" to "user sets constraints (CPA ≤ $15, daily budget ≤ $50) → Agent optimizes autonomously within bounds," representing the leap from Agent-as-assistant to Agent-as-operator.
Three principles
Documents are code. When the executor is an LLM, natural language becomes a first-class citizen for orchestration logic. This isn't a stopgap — it's a paradigm shift in how software is built.
80/20 + guardrails. 80% explicit guidance + 20% LLM reasoning is more reliable than 100% hardcoded logic — but only with well-designed guardrails and hard constraints at the tool layer to contain the risk in that 20%.
Determinism and probabilism are complementary. Safety floors are enforced with hardcoded constraints; flexible decisions are handled by LLM reasoning within the document framework. They don't replace each other — they collaborate in layers.
Orchestration and execution are table stakes now. The Growth Decision Layer — the real moat — is next. We're coming for it.









